
facefusion/facefusion
Fork: 3049 Star: 19898 (更新于 2024-11-29 10:45:11)
license: NOASSERTION
Language: Python .
Industry leading face manipulation platform
最后发布版本: 2.6.1 ( 2024-06-17 02:59:39)
FaceFusion
Industry leading face manipulation platform.


![]()
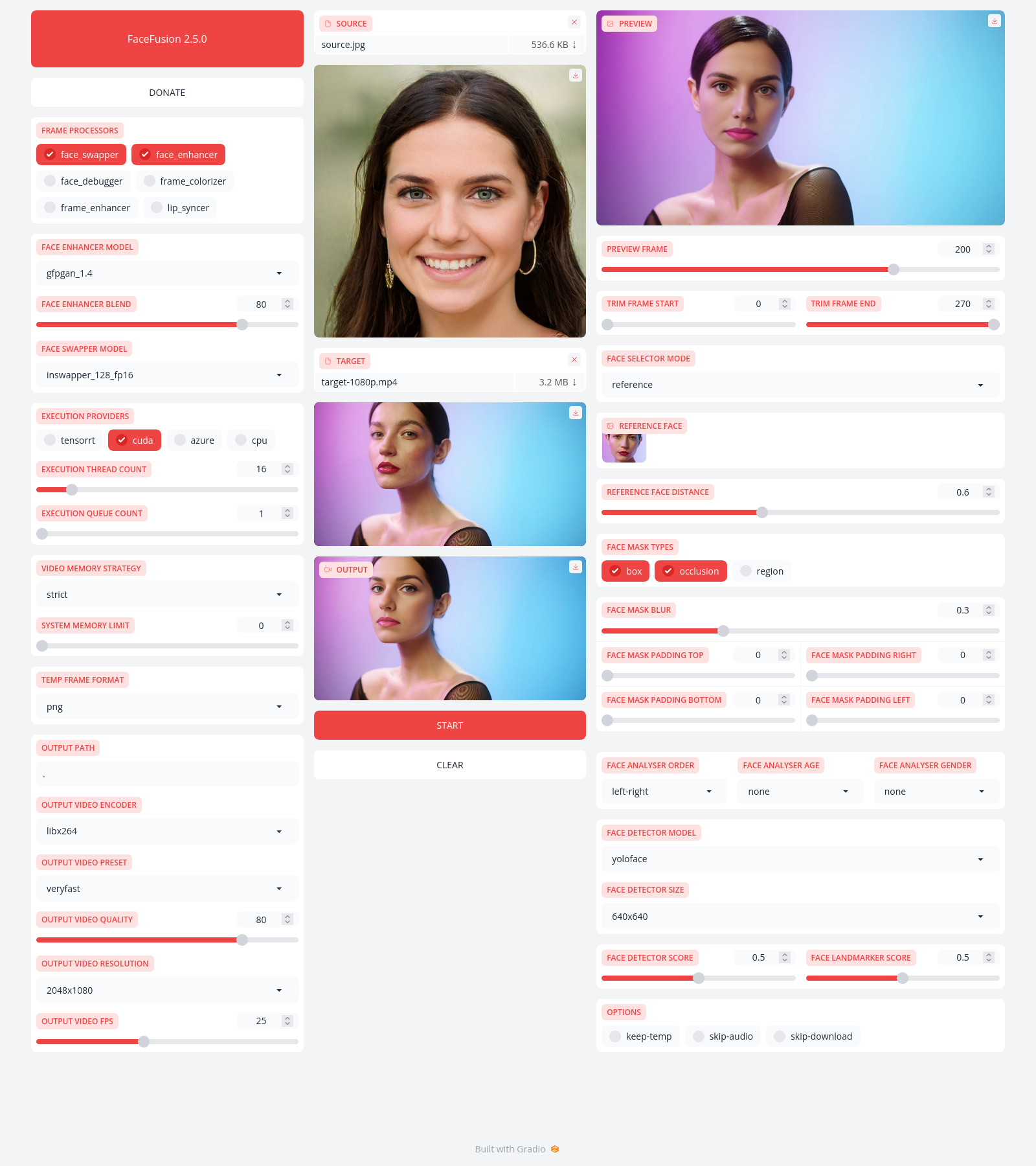
Preview
Installation
Be aware, the installation needs technical skills and is not recommended for beginners. In case you are not comfortable using a terminal, our Windows Installer and macOS Installer get you started.
Usage
Run the command:
python facefusion.py [commands] [options]
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
commands:
run run the program
headless-run run the program in headless mode
force-download force automate downloads and exit
job-list list jobs by status
job-create create a drafted job
job-submit submit a drafted job to become a queued job
job-submit-all submit all drafted jobs to become a queued jobs
job-delete delete a drafted, queued, failed or completed job
job-delete-all delete all drafted, queued, failed and completed jobs
job-add-step add a step to a drafted job
job-remix-step remix a previous step from a drafted job
job-insert-step insert a step to a drafted job
job-remove-step remove a step from a drafted job
job-run run a queued job
job-run-all run all queued jobs
job-retry retry a failed job
job-retry-all retry all failed jobs
Documentation
Read the documentation for a deep dive.
最近版本更新:(数据更新于 2024-09-17 09:45:26)
2024-06-17 02:59:39 2.6.1
2024-05-19 22:54:10 2.6.0
2024-05-08 03:36:16 2.5.3
2024-04-19 19:40:24 2.5.2
2024-04-13 17:37:37 2.5.1
2024-04-10 16:47:42 2.5.0
2024-03-20 17:08:49 2.4.1
2024-03-16 04:01:48 2.4.0
2024-02-14 21:25:41 2.3.0
2024-01-21 21:59:18 2.2.1
主题(topics):
ai, deep-fake, deepfake, face-swap, faceswap, lip-sync, lipsync, webcam
facefusion/facefusion同语言 Python最近更新仓库
2024-12-22 09:03:32 ultralytics/ultralytics
2024-12-21 13:26:40 notepad-plus-plus/nppPluginList
2024-12-21 11:42:53 XiaoMi/ha_xiaomi_home
2024-12-21 04:33:22 comfyanonymous/ComfyUI
2024-12-20 18:47:56 home-assistant/core
2024-12-20 15:41:40 jxxghp/MoviePilot