
v0.9.4
版本发布时间: 2021-11-16 13:19:37
microsoft/SynapseML最新发布版本:v1.0.4-spark3.5(2024-04-11 03:16:17)

Building production ready distributed machine learning pipelines can be a challenge for even the most seasoned researcher or engineer. We are excited to announce the release of SynapseML (Previously MMLSpark), an open-source library that aims to simplify the creation of massively scalable machine learning pipelines. SynapseML unifies several existing ML Frameworks and new MSFT algorithms in a single, scalable API that’s usable across Python, R, Scala, and Java.
Highlights
 |
 |
 |
 |
|
|---|---|---|---|---|
| General Availability on Synapse | ONNX on Spark | Responsible AI | Form Recognition and Translation | Reinforcement Learning |
| We are ready to help you productionalize on Azure Synapse Analytics | Distributed and hardware accelerated model inference on Spark | Understand opaque-box models, measure dataset biases, Explainable Boosting Machines | Parse PDFs and translate dataframes between over 100 languages | Contextual Bandit Reinforcement Learning with Vowpal Wabbit |
New Features
General ✨
- Renamed and rebranded! Microsoft ML for Apache Spark is now SynapseML
- New modular library sub-packages for standalone install of each major set of features
- Support Spark 3.1.2 and Scala 2.12
- Support
pip install synapsemlfor python bindings
ONNX on Spark 🕸
- ONNX model inference on Spark (#1152)
- Add documention and notebooks for ONNXModel evaluation (#1164)
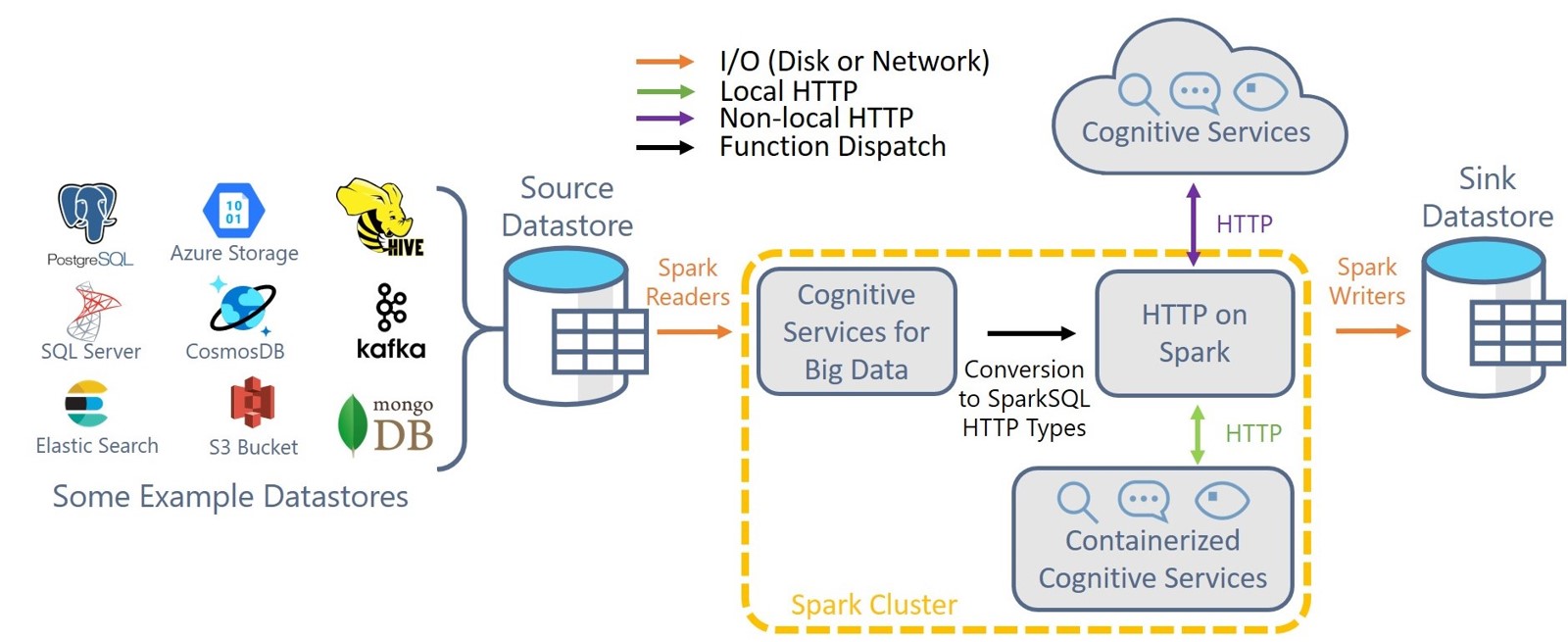
Cognitive Services for Big Data🧠
- Added Multilingual Translation APIs (#1108) (Tutorial)
- Added FormRecognition APIs (Invoice, IDs, BusinessCards, Layouts, Custom Models) (#1099) (Tutorial)
- Added the FormOntologyLearner to extract meaningful "ontologies" of objects from collections of forms
- Add notebook to Create a Multilingual Search Engine from Forms
- Updated Text Analytics API to V3.1 (#1193)
- Add redactedText to PIIV3 (#1247)
- Added Personally Identifying Information (PII) identification
- Added Read API
- Added Conversation Transcription API
- Cognitive service now support data exfiltration protected (DEP) VNET allowing for individualized security solutions on Synapse Analytics (Learn More)
- Added support for the m4a codec in Speech to Text models
- Added predictive maintenance notebook
- Added Cognitive Service overview notebook
- Added support for linked service authentication in Synapse Analytics
- Simple no-code support in in Synapse Analytics
Responsible AI at Scale 😇
- Added Additive Shapley Explanations (SHAP) for understanding the predictions of opaque-box models (#1077)
- New API for Locally Interpretable Model-Agnostic Explanations (LIME), now supports background distributions text models, and has the same API as SHAP (#1077)
- Added Measure transformers for Data Balance Analysis (#1218)
- Add more notebook samples for documentation (#1043)
- Documentation and notebooks for Interpretability on Spark
- Introduce Responsible AI section on website (Interpretability + DataBalanceAnalysis) (#1241)
- Adding document and notebook for Data Balance Analysis (#1226)
- Explainable Boosting Machines for performant and interpretable ML (Private preview on Synapse Analytics only)
Vowpal Wabbit 🐇
- Added ContextualBandit reinforcement learning (#896)
- Added Vowpal Wabbit Overview Notebook
LightGBM 🌳
- Added matrix type parameter and improve logic to automatically infer dataset sparsity (#1052)
- Added several parameters related to dart boosting type (#1045)
- Added chunk size parameter for copying java data to native (#1041)
- Added number of threads parameter (#1055)
- Added custom objective function to LightGBM learners (#1054)
- Added singleton dataset mode for faster performance and reduced memory usage (#1066)
- Add num iteration and start iteration parameters to LightGBM model (#1024)
- Added the average precision metric (#1034)
- Added overview notebook for LightGBM
- Moved to new streaming API for dense data to reduce memory usage
- Tuned chinking code for faster performance
Build and Infrastructure Improvements 🏭
- New Docusaurus website generation system
- E2E Tests on Synapse Analytics (#1014)
- Split library into separately installable subprojects (#1073)
- Added a unified logging and telemetry system (#1019)
- Modernized R wrapper generation
- New Automated Python test generation (#998)
- New extensible code generation system
- New two-tiered security for build secrets
- Update ubuntu version to 18.04
- Automated back-up ACR images
Additional Updates
Bug Fixes 🐞
- Enable backwards compatibility for
mmlsparkpython namespace imports (#1244) - Fix publishing to maven and pypi (#1242)
- Fix broken link to notebook in Data Balance Analysis doc (#1240)
-
min_data_in_leafmissing from dataset parameters in lightgbm (#1239) - Fix performance issue in interpretability notebooks (#1238)
- Fixed cognitive service errors (#1176)
- Fixed flaky tests
- Rename NERPii to PII
- Fixed cog service test flakes
- Fixed setLinkedService issues in Synapse (#1177)
- Improved LGBM error message for invalid slot names (#1160)
- Fixed generated python code (#1121)
- Updated notebookUtils class path (#1118)
- Fixed LIME NaN weight output (#1117, #1112)
- Fixed Guava version issue in Azure Synapse and Databricks (#1103)
- Fixed flakiness in spark session stopping
- Fixed result parsing for forms
- Fixed explainers returning wrong results when
targetClassesColis specified - Fixed CNTKModel issue due to catalyst bug on databricks (#1076)
- Fixed null handling in bing image response (#1067)
- Avoided strange issue with databricks json parser
- Fixed dependency exclusions and build secret querying
- Fixed issue in tabular lime sampler (#1058)
- Updated Bing search URLs (#1048)
- Refactored python wrappers to use common class (#758)
- Updated java params patch (#1027)
- Added missing returns in new python lightGBM model methods
- Stop R binding generation from failing silently
- Fixed conversation transcription participant column functionality
- Reduce verbosity to prevent RPC disassociated errors
- Fixed performance slip in Featurize
- Added timeout logic for speech to text
- Added ffmpeg time limit enforcing for flaky streams (#1001)
- Fixed upload python whl file to blob(#1000)
- Cleaned up python tests (#994)
- Fixed read schemas (#988)
- Made HTTP default concurrent timeout infinite
- Made HTTP rate limiting retry indefinitely
- Recommender Patch for Spark 3 Update (#982)
- Fix typo in text sentiment schema
- Changed ints to longs for offset and duration in STT
- Fixed processing sparse vector size
- Fixed Double User agent setting bug
- Fixed build warnings (#1080)
- Fixed build for new intellij
- Fixed livy dependency resolution
- Fixed pom for sbt dependencies (#1202)
- Fixed bug in
testGenparallelism - Auto-update packages in docker
- remove unused code
- Fix codecov logging of wrapper generation (#1098)
- Fix badge publishing
- Remove issue in scalastyle file for new IJ
Documentation 📘
- Add explicit pointer to HDI install
- fix typo (#990)
- Bump python install to top to make it clearer
- Add example CyberML notebook (#958)
- Add CyberML link to README.md (#989)
New Contributor Spotlight
We are excited to welcome several new developers to the SynapseML project.
 |
 |
 |
|---|---|---|
| Serena Ruan | Jason Wang | Wenqing Xu |
| Serena is an Engineer on the Azure Synapse team in Beijing. Within her first months working on SynapseML, Serena contributed Forms and Translator cognitive services, a unified logging and telemetry system, notebooks and documentation for every transformer and estimator, and a new docusaurus-based website. | Jason is a Principal Engineer on Microsoft's DSP team and is focused on large-scale responsible AI. Jason started his contribution streak with a new API for model explainability that unifies both SHAP and LIME. Jason has also contributed ONNX on Spark which dramatically broadens the scope of models that can be used in SynapseML. | Wenqing is a software engineer on the Azure Synapse team in Beijing. Wenqing has been instrumental in preparing SynapseML for General Availability. In particular, Wenqing added support for linked service authentication of cognitive services, extended E2E testing to Synapse Analytics, and added the PII identification service. |
 |
 |
 |
| Kashyap Patel | Rohit Agrawal | Jack Gerrits |
| Kashyap is an Engineer on Microsoft's DSP team working on improving the fairness of machine learning models. Kashyap contributed tools for assessing dataset bias without requiring a labelled dataset or model. | Rohit is a Senior Engineer on Microsoft's Cognitive Service team working on large-scale orchestration of intelligent services. Rohit modernized our Text Analytics Stack by updating to v3.0 and laid the groundwork for E2E testing on Synapse Analytics. | Jack is a Senior Engineer on the decision service and reinforcement learning team at Microsoft Research NYC. Jack contributed support for contextual bandit reinforcement learning with Vowpal Wabbit. |
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML
Jason Wang, Serena Ruan, Ilya Matiach, Jack Gerrits, Kashyap Patel, Wenqing Xu, Markus Weimer, Jeff Zheng, Nellie Gustafsson, Ruixin Xu, Martha Laguna, Markus Cozowicz, Rohit Agrawal, Daniel Ciborowski, Jako Tinkus, Tom Finley, Tomas Talius, Mitrabhanu Mohanty, Roy Levin, Anand Raman, William T. Freeman, Ryan Hurey, Sharath Chandra, Beverly Kodhek, Assaf Israel, Nisheet Jain, Ryan Hurey, Miguel Fierro, Dotan Patrich, Akshaya Annavajhala (AK), Euan Garden, Lev Novik, Guolin Ke, Tara Grumm, Keunhyun Oh, Vanunts Arsenii, Alexandr Severinov, David Lacalle Castillo, Ryosuke Horiuchi, Ashish Solanki, Matthieu Maitre, ONNX Team, Azure Global, Vowpal Wabbit Team, Light GBM Team, MSFT Garage Team, MSR Outreach Team, Speech SDK Team
Learn More
 |
 |
|
|---|---|---|
| Visit our new website for the latest docs, demos, and examples | Read more about SynapseML in the Microsoft Research Blog | Get started with SynapseML on Azure Synapse Analytics |
 |
 |
 |
| Read the Synapse Analytics Ignite Announcements | Read our Paper from IEEE Big Data '21 | Watch our ODSC Webinar on working with AI services at scale |